

Squirrel command line tool tutorial¶
This tutorial introduces seismological data handling with the squirrel command line tool.
The squirrel command line tool is a front-end to the Squirrel data
access infrastructure. In this tutorial,
we will download seismic waveforms organize them into a local file structure
and investigate various properties of the assembled dataset.
For an introduction on how to use the Squirrel framework in your own code, head on over to Examples: Squirrel powered data access.
Downloading data¶
The Squirrel framework contains functionality to download seismic waveforms and
station metadata from FDSN web services. With an appropriate dataset
configuration this can happen in a just-in-time fashion during processing.
However, sometimes we may prefer to completely download a dataset in advance.
This is one of the tasks for which the squirrel
command line tool has been created.
In this part of the tutorial we will download a few days of long period seismic waveforms from the BGR’s FDSN web service. We have selected a time window including the ground motions of the 2021 Mw 8.2 Alaska Earthquake and some of its aftershocks as they were recorded on German broad-band seismometers. Of course, you may choose a different time window, set of stations or FDSN web service, but please be responsible and do not download huge amounts of data just for testing.
Our first step is to create a local Squirrel environment with
squirrel init, so that all the downloaded files
as well as the database are stored in the current directory (our project
directory) under .squirrel/. This will make it easier to clean up when
we are done (rm -rf .squirrel/). If we omit this step, the user’s globally
shared Squirrel environment (~/.pyrocko/cache/squirrel/) is used.
Create local environment (optional):
$ squirrel init
To use a remote data source we can create a dataset description file and pass
this to the --dataset option of the various
squirrel subcommands. Examples of such dataset
description files are provided by the
squirrel template command. Running this command
without any further arguments will output a brief list of the available
examples. By chance there is one for accessing all LH channels from BGR’s FDSN
web service: bgr-gr-lh.dataset. We can save the dataset description file
with:
$ squirrel template bgr-gr-lh.dataset -w
squirrel:psq.cli.template - INFO - File written: bgr-gr-lh.dataset.yaml
The dataset description is a nicely commented YAML file and we could modify it to our liking:
--- !squirrel.Dataset
# All file paths given below are treated relative to the location of this
# configuration file. Here we may give a common prefix. For example, if the
# configuration file is in the sub-directory 'PROJECT/config/', set it to '..'
# so that all paths are relative to 'PROJECT/'.
path_prefix: '.'
# Data sources to be added (LocalData, FDSNSource, CatalogSource, ...)
sources:
- !squirrel.FDSNSource
# URL or alias of FDSN site.
site: bgr
# Uncomment to let metadata expire in 10 days:
#expires: 10d
# Waveforms can be optionally shared with other FDSN client configurations,
# so that data is not downloaded multiple times. The downside may be that in
# some cases more data than expected is available (if data was previously
# downloaded for a different application).
#shared_waveforms: true
# FDSN query arguments to make metadata queries.
# See http://www.fdsn.org/webservices/fdsnws-station-1.1.pdf
# Time span arguments should not be added here, because they are handled
# automatically by Squirrel.
query_args:
network: 'GR'
channel: 'LH?'
Expert users can get a non-commented version of the file by adding --format
brief to the squirrel template command.
Next, we must update the station meta-information for the time interval of
interest. This is done with the
squirrel update command. Channel information
intersecting with the given time interval will be downloaded (Fig. 1):
$ squirrel update --dataset bgr-gr-lh.dataset.yaml --tmin 2021-07-28 --tmax 2021-08-01
[...]
squirrel update:psq.client.fdsn - INFO - FDSN "bgr" metadata: querying...
squirrel update:psq.client.fdsn - INFO - FDSN "bgr" metadata: new (expires: never)
[...]
squirrel update:psq.cli.update - INFO - Squirrel stats:
Number of files: 2
Total size of known files: 87 kB
Number of index nuts: 160
Available content kinds:
channel: 120 1991-09-01 00:00:00.000 - <none>
station: 40 <none> - <none>
Available codes:
GR.AHRW..LHE GR.AHRW..LHN GR.AHRW..LHZ GR.AHRW.* GR.ASSE..LHE GR.ASSE..LHN
GR.ASSE..LHZ GR.ASSE.* GR.BFO..LHE GR.BFO..LHN
[140 more]
GR.UBR..LHZ GR.UBR.* GR.WET..LHE GR.WET..LHN GR.WET..LHZ GR.WET.*
GR.ZARR..LHE GR.ZARR..LHN GR.ZARR..LHZ GR.ZARR.*
Sources:
client:fdsn:b3ad21f2a866c178889cfdf4f493eba588a59543
Operators: <none>

Figure 1: The squirrel update command
ensures that the local channel metatadata is up to date. Channels epochs
intersecting with the time span specified with --tmin and
--tmax is downloaded or updated.¶
After fetching the channel information from the FDSN web service, it prints a brief overview of the contents currently available in our data collection.
If we run the update command a second time, Squirrel informs us that cached metadata has been used:
$ squirrel update --dataset bgr-gr-lh.dataset.yaml --tmin 2021-07-28 --tmax 2021-08-01
[...]
squirrel update:psq.client.fdsn - INFO - FDSN "bgr" metadata: using cached (expires: never)
[...]
Only if we call the update command with a yet unknown time span, it will make
new queries. It is also possible to set an expiration date for metadata from
this data-source in the dataset configuration
(expires).
By default, only channel information is made available with squirrel
update. If we later need the instrument response information of the seismic
stations of the data selection, we can add the --responses option to
squirrel update (Fig. 2):
$ squirrel update --responses --dataset bgr-gr-lh.dataset.yaml --tmin 2021-07-28 --tmax 2021-08-01
[...]
Available content kinds:
channel: 120 1991-09-01 00:00:00.000 - <none>
response: 150 1991-01-01 00:00:00.000 - <none>
station: 40 <none> - <none>
[...]

Figure 2: With the --responses option also instrument response
information is downloaded with
squirrel update.¶
So now we also have response information containing details about how the seismometers convert physical ground motion into measurement records.
Next we must give permission to Squirrel to download data given certain
constraints. Squirrel will only download waveform data when it has a so-called
promise for a given time span and channel. These promises must be explicitly
created with the --promises option of
squirrel update. We are only interested in
vertical component seismograms at this point, so we restrict promise creation
to channels ending in ‘Z’ (Fig. 3):
$ squirrel update --promises --dataset bgr-gr-lh.dataset.yaml --tmin 2021-07-28 --tmax 2021-08-01 --codes '*.*.*.??Z'
[...]
Available content kinds:
channel: 120 1991-09-01 00:00:00.000 - <none>
station: 40 <none> - <none>
waveform_promise: 40 2021-07-28 00:00:00.000 - 2021-08-01 00:00:00.000
[...]

Figure 3: With the --promises option of
squirrel update selected time intervals on
selected channels are marked as downloadable. The promises act as
placeholders for the real waveforms which are not yet available.¶
Why do we need a concept involving “promises” you may ask. Well, besides giving us a tight leash on what Squirrel will eventually download, it solves a bookkeeping problem: normally, when resolving a promise and if the download succeeds, the promise is simply removed. When it fails because of a temporary problem (e.g. connectivity), it is kept so that the download can be tried again later. If it however fails permanently, maybe because the waveform is not available on the server, the promise is deleted, so that we do not repeatedly query the server for non-existent data. Finally, if we want to freeze the dataset, we can just remove all remaining promises and no further download attempts will be made. We think that these benefits outweigh the conceptual complexity added with the promises.
After setting up the promises, to actually download the waveforms, we can now
use the squirrel summon command (Fig. 4):
$ squirrel summon --dataset bgr-gr-lh.dataset.yaml --tmin 2021-07-28 --tmax 2021-08-01

Figure 4: The with the squirrel summon
command, matching promises are resolved by downloading the actual waveforms
if possible. On success, the placeholder promises are removed.¶
Finally, let’s have a look at the waveforms. We can use an experimental Squirrel-powered version of the Snuffler application to interactively explore the dataset (Fig. 5):
$ squirrel snuffler --dataset bgr-gr-lh.dataset.yaml
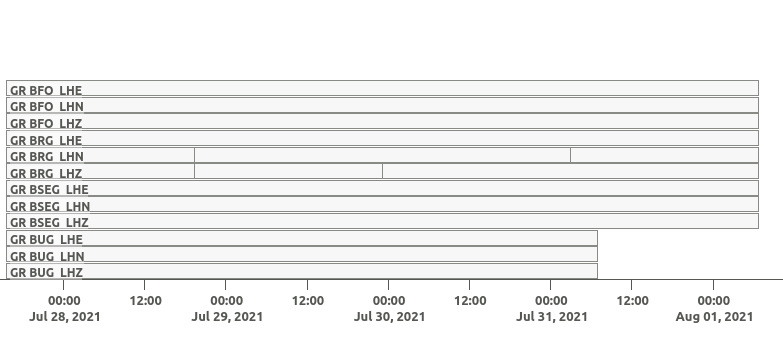
Figure 5: Screenshot from squirrel snuffler
showing the available waveforms after successfully summoning the dataset.¶
The downloaded waveforms include the signals from an Mw 8.2 earthquake which occurred on 2021-07-29 at 06:15 UTC (Fig. 6).
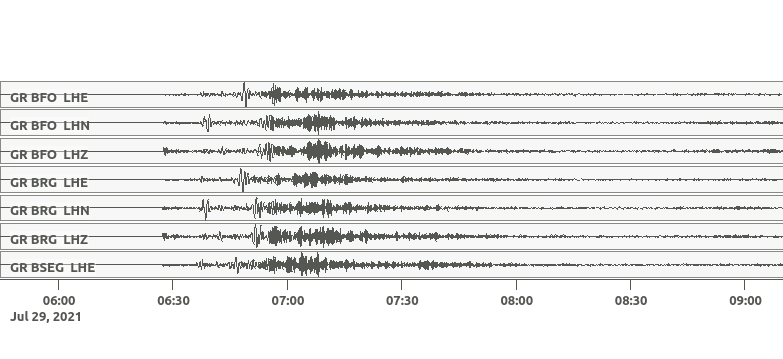
Figure 6: Screenshot from squirrel snuffler
after zooming in on the waveforms from the Mw 8.2 Alaska earthquake. The
earthquake was located at a depth of 28 km and 104 km SE of Perryville,
Alaska in the Aleutian megathrust. It was followed by some smaller
aftershocks. The authorities issued a Tsunami warning but only a small
Tsunami of 30 cm was observed and the warning was lifted shortly after.¶
Waveforms are always downloaded in blocks of reasonable size, therefore the
downloaded time frame may be slightly larger than the requested time span. The
downloaded dataset can be incrementally extended by running
squirrel update and
squirrel summon multiple times. Only missing
data blocks are downloaded when running
squirrel summon. Other waveforms available
through the current Squirrel data collection are also considered to avoid
unnecessary downloads.
Dataset conversion¶
So far the waveforms have been downloaded into a special cache directory maintained by Squirrel. Using the data from there is useful if we will later want to extend the dataset. However, sometimes we want to have full control and so want to create our own waveform archive in a portable form.
To copy the data downloaded in the previous section into a handy directory
structure, we can use the squirrel jackseis
command. With its --out-sds-path a standard SDS data directory with
day-files in MSEED format is created:
$ squirrel jackseis --dataset bgr-gr-lh.dataset.yaml --out-sds-path data/sds
$ tree data/ # Use `ls`, if `tree` is not installed.
data/
└── sds
└── 2021
└── GR
├── BFO
│ └── LHZ.D
│ ├── GR.BFO..LHZ.D.2021.208
│ ├── GR.BFO..LHZ.D.2021.209
│ ├── GR.BFO..LHZ.D.2021.210
│ ├── GR.BFO..LHZ.D.2021.211
│ ├── GR.BFO..LHZ.D.2021.212
│ └── GR.BFO..LHZ.D.2021.213
├── ...
Station metadata is exported when adding the --out-meta-path option to
squirrel jackseis. By default, this exports the
metadata in StationXML format to the given file path:
$ squirrel jackseis --dataset bgr-gr-lh.dataset.yaml --out-meta-path meta/stations.xml
We will use the dataset consisting of the waveforms in data/sds and the
station meta-data in meta/stations.xml as a “local dataset” in the
following sections.
Local datasets¶
To inspect some local data holdings, we can use the Snuffler application by calling
squirrel snuffler. Files and directories given
to the --add option are made available. File formats are usually
autodetected and directories are recursively scanned for any readable files.
To look at the dataset that we have created in the previous section of the tutorial, use:
$ squirrel snuffler --add data/sds meta/stations.xml
The --add option is part of a group of standardized options to configure the run-time data collection of
Squirrel based programs. If we find ourselves repeatedly specifying the same
file paths over and over again, it may be a good idea to tie them together in a
dataset description file. An example of such a file for local datasets can be
obtained with squirrel template local.dataset. For a nicely organized
project directory, we may want to place the dataset description file into a
subdirectory config:
$ mkdir config
$ squirrel template local.dataset > config/alaska.dataset.yaml
$ nano config/alaska.dataset.yaml # or use your favourite text editor
Let’s modify the file so that our precious waveforms and metadata are found:
--- !squirrel.Dataset
# All file paths given below are treated relative to the location of this
# configuration file. Here we may give a common prefix. For example, if the
# configuration file is in the sub-directory 'PROJECT/config/', set it to '..'
# so that all paths are relative to 'PROJECT/'.
path_prefix: '..'
# Data sources to be added (LocalData, FDSNSource, CatalogSource, ...)
sources:
- !squirrel.LocalData # This data source is for local files.
# These paths are scanned for waveforms, stations, events.
paths:
- 'data/sds'
- 'meta/stations.xml'
# Select file format or 'detect' for autodetection.
format: 'detect'
The paths in the dataset description file are relative to the location of this
file itself. The value of path_prefix is prepended to all paths. Because
alaska.dataset.yaml is in the projects subdirectory config, we have set
path_prefix to '..'. With this, the rest of the paths can be given
relative to the project directory root.
Now we can look at our waveforms by just passing the dataset description file
to squirrel snuffler:
$ squirrel snuffler --dataset config/alaska.dataset.yaml
With an appropriate configuration of the dataset, local and remote data sources
can be combined. It is also possible to add multiple datasets to a Squirrel
program or to combine --dataset and --add. Like this, the runtime data
collection can be flexibly composed at program startup. Squirrel maintains
indexes of known files, so that repeated program startups are extremely
efficient. This approach works well with datasets of up to about 100k - 1M
files. For larger data archives, it is possible to create persistent
selections, which we will cover later.
Dataset inspection and querying¶
In this part of the tutorial, we will explore some more
squirrel subcommands useful when checking data
availability or to hunt down data problems.
Commands like squirrel snuffler will always
first index any unknown files. For large data archives, this can take quite
some time. To perform the indexing in advance use the
squirrel scan subcommand:
$ squirrel scan --dataset config/alaska.dataset.yaml
To obtain a visual representation of the data availability over time on the
terminal use squirrel coverage:
$ squirrel coverage --dataset config/alaska.dataset.yaml
Use --tmin and --tmax to narrow down the displayed time span.
To get all data codes identifying the various stations/channels available in a data collection, run:
$ squirrel codes --dataset config/alaska.dataset.yaml
The returned codes (aka channel IDs / stream IDs / NSLC codes) have the form
NET.STA.LOC.CHA.EXTRA, where the first four follow the FDSN conventions and
the optional EXTRA code is for derived data streams within the Squirrel
framework.
Several squirrel subcommands allow querying
for channels using patterns given to the --codes option. For example
squirrel nuts lists index entries. Nuts are the
smallest units of information in the Squirrel framework. To obtain an inventory
listing of everything related to the vertical component of station BFO, we may
run:
$ squirrel nuts --dataset config/alaska.dataset.yaml --codes '*.BFO.*.??Z'
Or, to find out what files in our collection contain information about station BFO, run:
$ squirrel files --dataset config/alaska.dataset.yaml --codes '*.BFO.*.*'
Similarly, it is possible to query by time span (--tmin, --tmax) or
content kind (--kind), ie. waveform, channel, response, etc.
Conceptually, we should remember that the collection options build up a data collection and the query options are used to query information from that collection. The query options never change the collection itself.
Earthquake catalogs¶
Squirrel can also be used to retrieve and incrementally update earthquake catalog information from a few selected online catalogs.
Online catalogs can be added to the
sources in a dataset description.
In this example we will use events with a magnitude above 7.0 from the GEOFON
earthquake catalog:
--- !squirrel.Dataset
path_prefix: '..'
sources:
- !squirrel.LocalData # This data source is for local files.
paths:
- 'data/sds'
- 'meta/stations.xml'
- !squirrel.CatalogSource
catalog: geofon
query_args:
magmin: 7.0
To make sure that the local excerpt of the catalog is up to date for a given
time span, we must call squirrel update with
the dataset description and the desired time span:
$ squirrel update --dataset config/alaska.dataset.yaml --tmin 2021-07-28 --tmax 2021-08-01
Again, as we have seen with waveforms and station metadata, Squirrel is lazy
and tries to avoid duplicate downloads of event information. It uses the
locally cached information when possible. To make our dataset aware of updates
in the upstream catalog, we can to set an expiration time for the cached
information
(expires) or a time
period for which new data is considered unreliable
(anxious).
Large datasets and persistent selections¶
So far, the runtime data selection used in each squirrel command has been
composed at each startup. For example when running squirrel snuffler --add
data/sds meta/stations.xml, a temporary database is created with all the
content given to --add. This temporary database is deleted again when
squirrel snuffler exits. The advantage of this approach is that we can very
flexibly combine what data should be available in each processing step. The
disadvantage is that the creation of the temporary database takes some time and
leads to slow program startup for large datasets. To use a persistent instead
of a temporary database, use the --persistent option. This option takes the
name of the persistent selection which will be created or used as an argument.
For example, to create a persistent selection named alaska, and add all
files in data/sds, run:
$ squirrel snuffler --persistent alaska --add data/sds
To look at the newly created selection:
$ squirrel snuffler --persistent alaska
We can also add further data to the selection:
$ squirrel snuffler --persistent alaska --add meta/stations.xml
It is possible to create multiple persistent selections but each one adds some internal bookkeeping overhead which can impact the overall performance of the database.
Existing persistent selections can be listed:
$ squirrel persistent list
To remove again the persistent selection alaska:
$ squirrel persistent delete alaska
Persistent selections trade flexibility against program startup time.
Summary¶
The Squirrel framework provides a unified
interface to query and access seismic waveforms, station meta-data and event
information from local file collections and remote data sources. For prompt
responses, a database setup is used under the hood. To speed up assemblage of
ad-hoc data selections, files are indexed on first use and the extracted
meta-data is remembered for subsequent accesses.
The squirrel tool provides some of the features of the Squirrel
framework on the command line. In this tutorial, we have seen how we can use it
to perform some every day seismological tasks such as downloading data from
FDSN web services, dataset conversion and inspection.
For an introduction on how to use the Squirrel framework in your own code, see Tutorial: writing a Squirrel based tool to calculate hourly RMS values.